
「アニメ絵や美少女絵をAIで生成したい!」
「Animagineが凄いって聞いたけど実際どうなの?」
このような疑問や希望を持たれている方も多いのではないでしょうか?
そこで、本記事では話題のオープンアニメ画像生成モデル「Animagine」について解説していきます。
なお、Google Colabで構築する方法や、StableDiffusionのローカル構築など、複雑な内容は関連記事に任せ、本記事では「日本一簡単な画像生成ガイド」を目指して書き進めます。
まだ画像生成AIに触れたことがない方や、苦手意識を持っている方でも、本記事を読み進めるだけで実際にAnimagineを動かし、思うような美少女画像が生成できるようになるはずです。
※説明が複雑に感じる場合はいきなり本題の「Part3」から読み進めてください。
大枠の使い方や、Animagineで生成できる画像のクオリティが“体験”できる様な造りになっているので、ぜひ実際に手を動かしながら読み進めてくださいね!
目次


Part1.画像生成AIとは?

そもそも「画像生成AI」とは、という点から簡単に解説します。
画像生成AIは、学習済みデータを活用して、ユーザーの指示から新たな画像を“生成”するAIモデルのことです。
例えば、本記事のテーマであるAnimagine XL 3.0で「野原を駆け回る犬」という指示を生成AIに出すと、上の画像が出力されました。この画像はオリジナルの画像であり「Seed値」を固定しない限り、同じ指示(プロンプト)でも同じ画像が生成されることはありません。
また、使用する画像生成AIモデルによって、学習データの内容が異なるため、やはり同じ指示(プロンプト)でも異なる画像が生成されます。
大まかな仕組みとして、画像生成AIは、機械学習手法である「ディープラーニング(深層学習)」によって、大量のデータを自ら分析学習しており、ユーザーの指示を受けて学習データから再構築していきます。
なお、生成AIには「VAE」や「GAN」「拡散モデル」など、様々な生成モデル(生成の手法)が有ります。
Part2.Animagine XLとは?
「Animagine」は、特にアニメイラスト生成を得意とする画像生成AIモデルです。2024年1月10日にAnimagine XLのV3.0が、2024年3月18日にV3.1が公開されました。
既に人気の高かった「Animagine XL 2.0」をファインチューニングしたモデルで、高い精度でイラストが生成できる点や、NSFW(Not Safe for Work:職場で開けない意味、つまりアダルトコンテンツや暴力、残酷な表現など)にも対応している点から大きな注目を集めています。
また、Chackpointモデル単体、つまりLoRA不要で、アニメキャラやアニメタイトルが反映できる点も大きな魅力です。
なお、大きな話題となった「Midjourney」や「Dream Studio」などのサービスは、画像生成AIであると同時に画像生成AIを組み込んだ“サービス”でもあります。
一方で今回紹介する「Animagine XL」は生成AIモデル“そのもの”です。つまり、純粋なAnimagine XLというサービスは存在しません。Chackpointモデルとしてローカル構築したStableDiffusion内で使用するなどが、一般的な使用方法となります。
なお、使用用途として私的利用はもちろん、商用利用や改変、特許使用などすべて無料で許可されています。
Part3.【Animagine XL】アニメ美少女画像を生成してみよう!
早速Animagine XL3.0を使って、実際にアニメ美少女画像を生成してみましょう!
先ほども紹介しましたが、本章では「Google Colab」や、StableDiffusionのローカル構築などは使用せず、無料公開されているAnimagine XL3.0のdemoを使って画像をAI生成していきます。
方法として非常に手っ取り早く、手軽に取り組める反面、Loraや細かい設定には不向きですので、更にこだわった画像生成がしたい方は、本記事で色々試した後、以下の関連記事にもトライしてみてください。
関連記事:Stable Diffusion web UI(AUTOMATIC1111版)をインストールする方法【Windows/Mac】
Step 1Spaces/Animagine XL3.0にアクセス
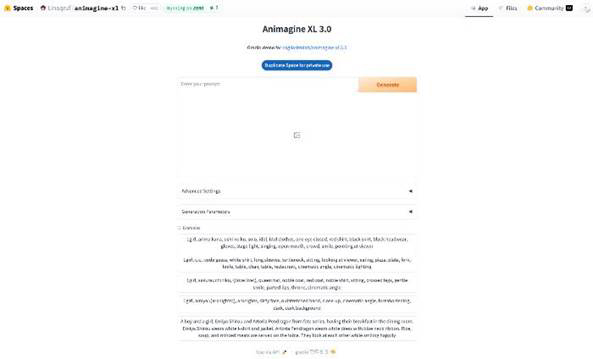
Spacesで公開されている「Animagine XL3.0」にアクセスします。
登録や環境構築が不要で、即座にAnimagine XL3.0による画像生成が体験できます。
Step 2プロンプトを入力

[Enter your prompt]の部分に、プロンプト(指示文)を記入していきます。
CaliostroLabで公開されている情報によると、上記のような構成でプロンプトを作成するのがおすすめです。
まずは生成したい対象「1boy/1girl」などを記入、続いて「アニメキャラクターの名前」「アニメ作品の名前」を入力。
「シチュエーションや状況などを説明」した後、最後に[masterpiece][best quality]などの「クオリティタグ」という順番ですね!
プロンプトについては、よりAIに正しく情報を伝えるための“型”が、AIモデルによって異なります。
とはいえ、あくまで「この方が伝わりやすい」程度の話であり「上記の順番でないといけない」というルールではありませんよ!
DeepLなどを使って、まずは作成したい画像の内容を自由に記入してみても良いでしょう!
Tipsモデルとなる画像やイラストがある場合
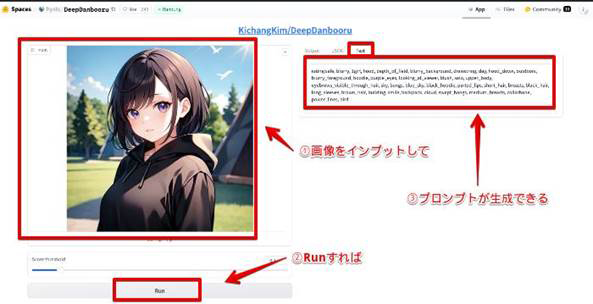
モデルとしたい画像やイラストがある場合に使えるテクニックとして、同様にSpacesから利用できる「DeepDanbooru」を使用する方法がおすすめです。
DeepDanbooruに、モデルにしたい画像をアップロードすれば、自動でAIが、その画像を“プロンプト化”してくれますよ!
どこまで詳細に要素を抜き出すかも指定できるため、こちらもぜひ使ってみてください。
Step 3設定
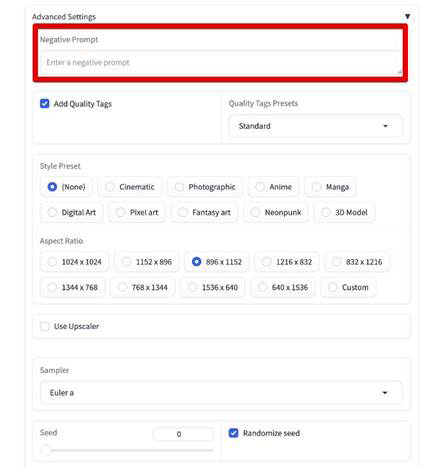
続いて設定をしていきます。
ちなみに、プロンプトだけ記入すれば、特に細かい設定をしなくても、全て初期値のまま生成は可能です。
そのため「とりあえず生成したい!」という方は「Step4.」に進んでいただいてもOKですよ!
「Advanced Settings」を開いて「Negative Prompt」を入力します。
ネガティブプロンプトは、簡単に言うと表示したくない要素を指示するプロンプトです。
この部分には「指の崩れ」など画像生成AIでありがちなエラーを入力して、先手を打っておきます。
・bad anatomy
・bad hands
・text
・error
・missing fingers
・worst quality
・low quality
等を入れておきましょう!
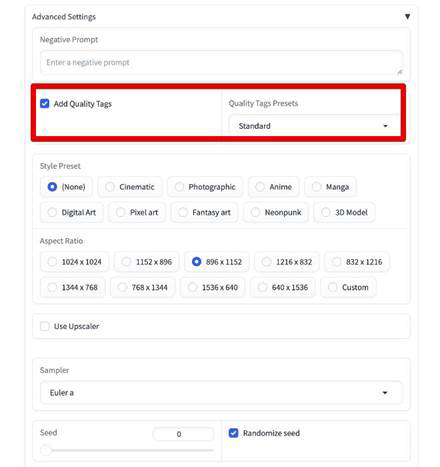
「Add Quality Tags(クオリティタグを加える)」は、先ほど紹介した構成に従って、既にプロンプト内にクオリティタグを記入している場合、特に気にしなくてOKです。
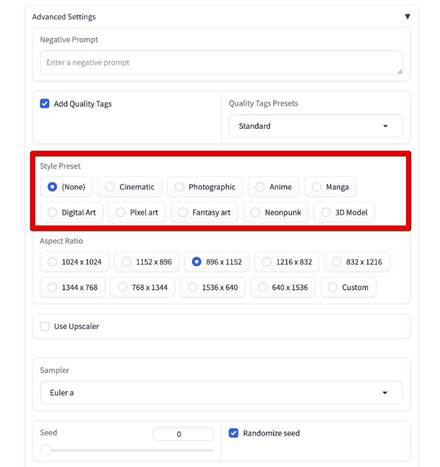
「Style Preset(スタイルプリセット)」は、生成される画像のスタイルを決定できます。
最初は[None]で生成し、気に入らなければ変化させていくというような使い方で良いでしょう。
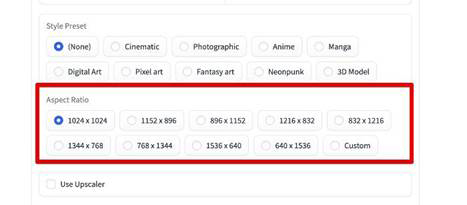
「Aspect Ratio(アスペクト比)」で、アスペクト比を指定します。
カスタムも選択できるので、ほしい画像サイズを指定してください。
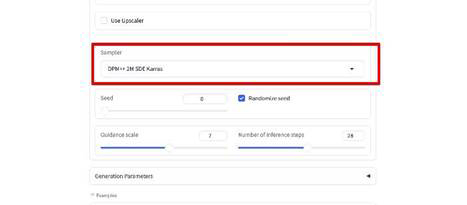
「Sampler(サンプラー)」は、実は重要で、同じプロンプト、同じ設定だとしても、サンプラーによって生成される絵のクオリティは大きく変わります。
ただし、あなたの求める絵柄にどのサンプラーが合うかは実際に生成しながら確かめてみるのがおすすめです。
筆者の個人的なおすすめは「DPM/+/+2M SDE Karras」です。
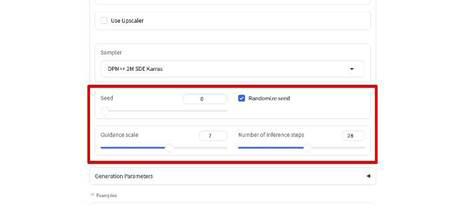
Seedは、最初の生成は「Randomize seed(ランダムなシード値)」でOKです。
また「Guidance scale(CFGスケール)」「Number of inference steps(ステップ数)」はそれぞれ「5〜7」「20〜30」がおすすめです。
Step 4AI画像生成
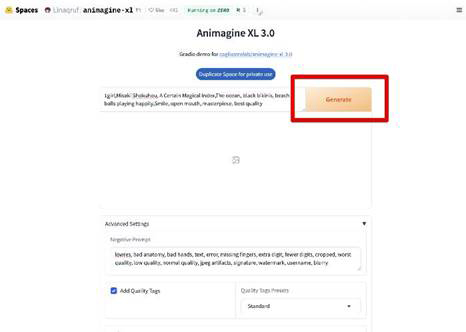
ここまで完了したら上に戻って[Generate]をクリックしましょう。
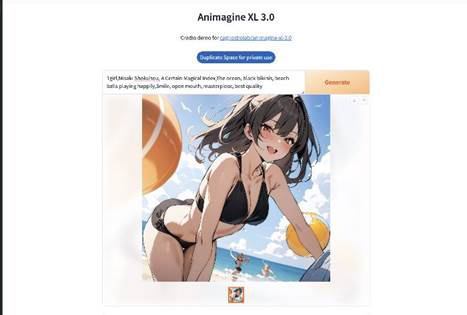
しばらく待つと画像が生成されます。
ここで、思い通りの画像が生成できた方と、そうでない方がいらっしゃるはずです。
AIによる画像生成は、ある程度のランダム性が前提であり、うまく生成する為には試行錯誤が欠かせません。設定やプロンプトを調整しながら、何度も画像を生成してみてください!
好みの画像が生成された場合は、設定のシード値をランダムにせず、固定した状態で更に細かい調整をしていきましょう!
Part4.ソフトを使ってAI画像生成したい方はFilmoraがおすすめ
ここまでAnimagine XLを使ったAI画像生成の概要や具体的な方法について解説してきました。
本章では、より手軽にAI画像生成ができるソフト「Filmora」について、紹介します。
4-1.Filmoraとは?
Filmoraは世界的ソフトウェア企業である「Wondershare社」が開発・公開しているソフトで、手軽で簡単に質の高いAI画像が生成できるだけでなく、ハイクオリティな動画編集が可能、Animagineで生成したAI画像と併せて使えば、クリエイティブな活動が加速する最先端ツールです。
ソフトの特徴は以下の通りです。
・高度な動画編集機能の数々
・動画編集が初めての方でも使いこなせる直感的な操作感
・1,000万点を超える豊富な搭載素材/テンプレート/エフェクト
・800種類以上のLUTフィルター
・マルチプラットフォーム対応でPC/スマホ/タブレット/ブラウザから使用可能
など、多くの魅力から世界150カ国以上で1億人以上のユーザーを抱え、動画編集のプロから完全初心者まで幅広く愛用する超人気ソフトとなっています。
4-2.Filmoraで美少女画像を生成してみよう!
Filmoraに搭載された「画像生成AI」機能を使って、美少女画像を生成する手順を見ていきましょう!
また、今回は「AI画像生成」を使用しますが、AI画像スタイライ機能も手軽に画像をスタイライズできるおすすめのAI機能です。
関連記事:【2024年版】AI美女・美少女画像が生成できるアプリ&サイト6選
Step 1AI画像生成を起動
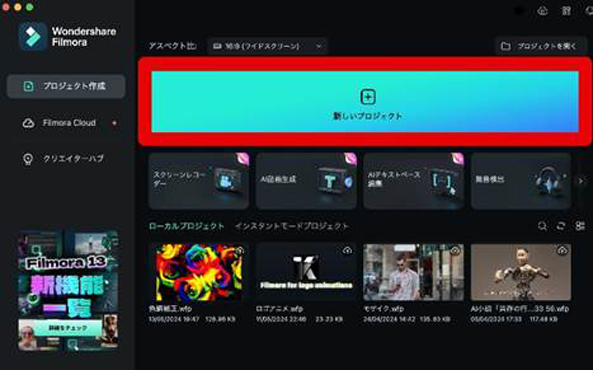
Filmoraを起動し、[新しいプロジェクト]を選択します。
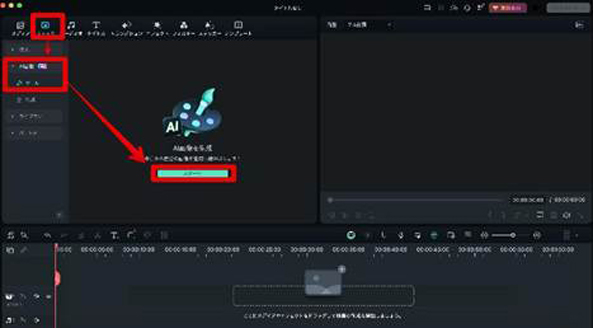
動画編集画面が立ち上がったら、[ストック]タブから、[AI画像]>[ツール]>[スタート]の順で進み、AI画像生成機能を立ち上げましょう。
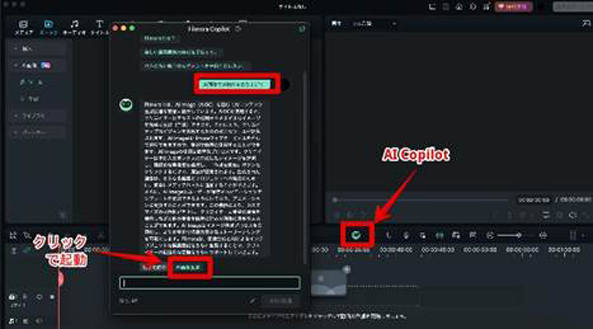
また、先述のAI Copilotを使って、AI画像生成を直接起動することも可能です。
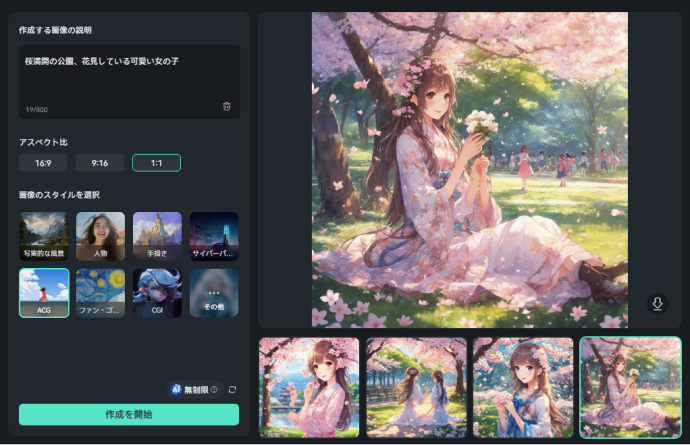
Step 2作成する画像の説明
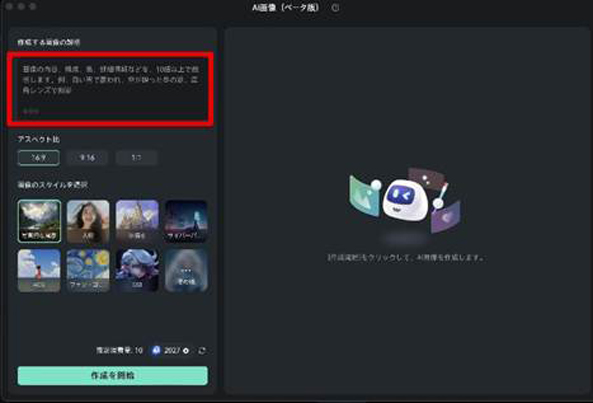
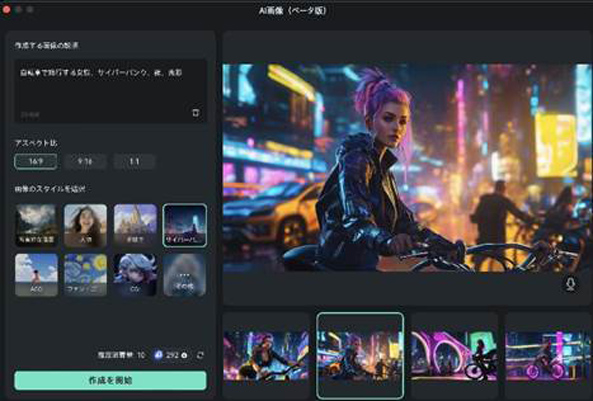
AI画像生成が起動したら、まずは「作成する画像の説明」に、生成したい画像の詳細を記述していきます。
Animagine XLとは異なり、日本語入力にも対応している点は、多くの方にとってより手軽に利用できるメリットでしょう。
Step 3画像生成
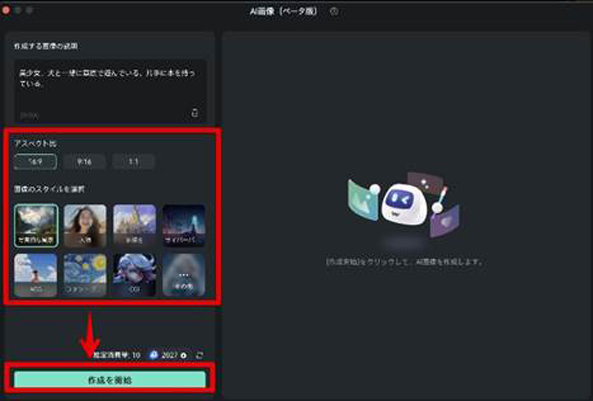
アスペクト比と、画像のスタイルを指定した上で、[作成を開始]をクリックしましょう。
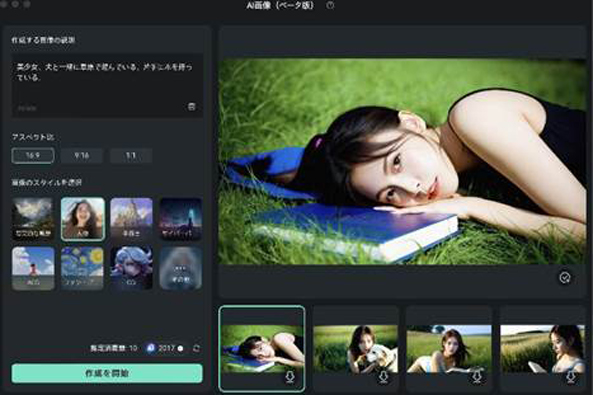
この際、選択するスタイルで大きく生成される画像の仕上がりは変化します。
設定項目が少なく、スタイルを選択するだけでプリセット的に画像が変化させられる点も大きな魅力ですね!
Step 4画像の保存
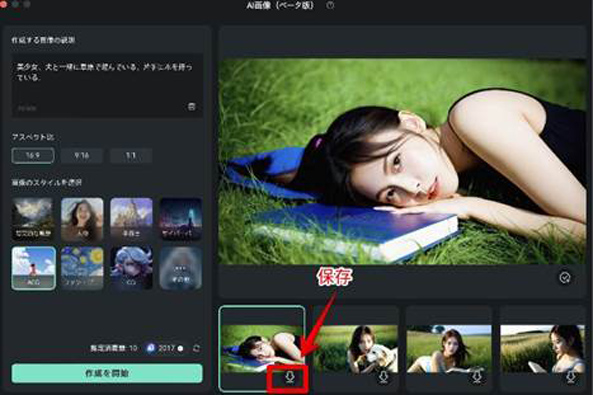
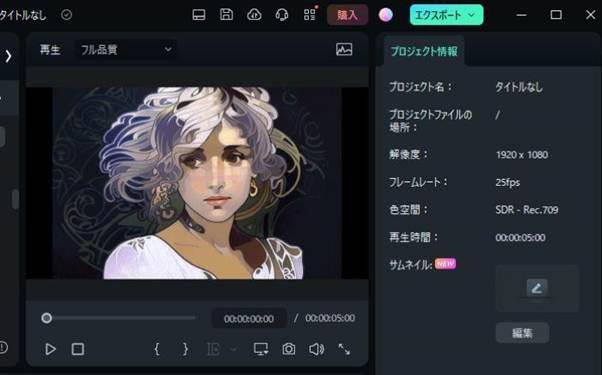
指示と設定から、画像候補が4枚生成されます。
今回は[人物]をスタイルで選択したため、写真と見分けがつかないような画像が生成されました。
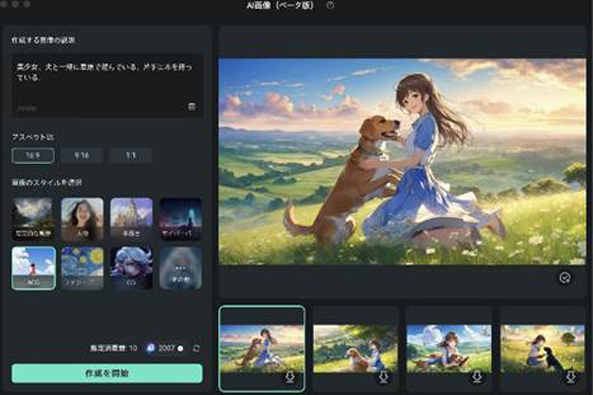
対して例えば[ACG]を選択すると、同じ指示の画像でも、テーマは保持されたまま、スタイルの大きく異なる画像が生成できましたね!
気に入った画像は全て[保存]をクリックして、保存しておきましょう!
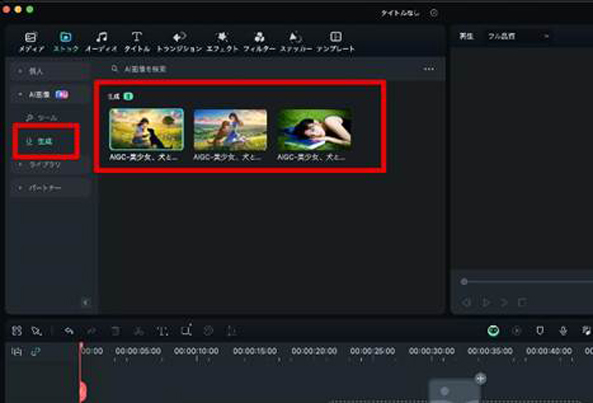
なお、保存した画像はローカルに加えて、「AI画像」内の[生成]にも自動保存されます。
そのため、そのまま動画素材としても活用できますよ!
4-3.FilmoraのAI機能
Filmoraには、非常に画像生成AIを含む多くのAI機能が搭載されています。
画像生成AIについては、後ほど手順解説とともに詳しく解説していくため、本章では他にどんなAI機能が搭載されているかについて見ていきましょう!
機能1.AI動画翻訳
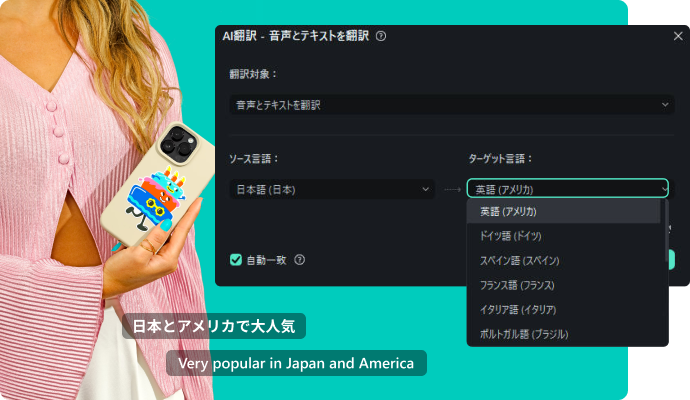
AIによる動画内音声の翻訳機能です。
ワンクリックで、動画内音声を翻訳文字起こしし、同時に翻訳テロップ作成と翻訳ナレーション音声が生成できます。
翻訳がまだされていない映画の翻訳や、外国語学習、ビジネスシーン、海外への発信など、多くのシーンで役立つ機能です。
機能2.AI動画生成
シナリオや台本を入力するだけで、AIが動画を生成してくれる機能です。
上の画像は、実際に機能を使用して生成した直後のものです。
動画に加えて、テロップや、BGM、ナレーションが自動で生成されています。
動画の原型をまずは作成するのにも適しており、自分でさらに編集を加えていけば、よりオリジナリティのある質の高い動画に仕上げられるでしょう!
機能3.AI Copilot
専用のチャット型AIアシスタントが「AI Copilot」です。
Filmoraや動画編集について知り尽くしたAIアシスタントが搭載されており、疑問や質問に対して、即座に回答してくれます。
特に動画編集初心者の方におすすめの機能で、熟練した動画編集のプロがいつでも横にいる様な感覚で、安心感を持って動画編集に取り組めるでしょう。
その他の機能
上記以外にも、例えば以下の様な機能が全て簡単なマウス操作で使用可能です。
| 機能名 | 機能概要 |
| AIボーカルリムーバー | 楽曲のボーカルとバックサウンドを分離する |
| AIスマートマスク | 動画・画像内の被写体を自動で切り抜き |
| AIテキストベース編集 | 動画内音声をテキストに変換する |
| AI音楽ジェネレーター | 簡単な指示と選択だけで思い通りのロイヤリティフリー音楽が生成できる |
| AIサムネイルエディター | SNSで視聴者の目を引くサムネイルをAI作成できる |
| AIノイズ除去 | 動画内の音声ノイズを自動で除去する |
| AIコピーライティング | 動画の情報を的確に文章化する |
| 自動字幕起こし | 動画内音声をAI認識し自動で字幕テロップを作成 |
Filmoraを使えば本来多くの時間と手間を要していた作業や処理が、AIによるサポートや生成で、誰でも簡単に実現できます!
画像生成に特化したAnimagineと併用すれば、よりクリエイティブの幅も広がるでしょう。
Part5.AI画像生成のよくある質問
最後に、AI画像生成について、多くの方が気になる質問と回答について紹介していきます。
違法性や、欠点、注意点など、実際に使用していく上で重要なポイントですので、ぜひ目を通してくださいね!
質問1AI画像生成は違法?
AI画像生成という行為自体に違法性はありません。
ただし、生成した画像が著作権や商標権、パブリシティ権などを侵害しているとみなされるケースは存在します。先述の通り、AIは大量のデータから学習することで、新たな画像を生成します。
こういった仕組み上、作成者の意図にかかわらず、モデルの学習データ内に著作物が含まれており、それが生成した画像に強く反映された場合、著作権などを侵害してしまう恐れがあるのです。
アメリカでは画像生成AIを開発している企業に対して、著作権者が集団訴訟を起こすといった動きも現実に起こっています。
参考:アメリカのAI訴訟に新たな動き:アーティストによる著作権請求に対する初の裁定を徹底解説|Open Legal Community
生成AIの著作権侵害については、現在も世界中で議論されており、厳密なルールが設定されているわけではありませんが、既存著作物への依拠性が明らかである場合は、公開しないようにするのが無難でしょう。
質問2AI画像生成の欠点やデメリットは
AI画像生成をしていく上で、欠点やデメリットとされるのは主に以下の3点です。
・著作権侵害のリスク
・倫理的な問題
・生成結果の品質
先ほど質問1で解説した著作権侵害のリスクに加えて、人種差別や性差別、暴力的、卑猥な画像を生成することによる倫理的なリスクも存在しています。
今後、更にAI画像生成のクオリティが高まり、写真と見分けがつかなくなってしまった場合は、更にこのリスクが顕在化するかもしれません。
最後に、生成結果の品質についても現状バラつきがある点がデメリットでしょう。自分でイラストを描く場合、意図しない出力やエラーは防ぐ事ができます。
一方、発展途上の技術である画像生成AIの場合は「指が7本ある」「腕が3本ある」など、意図しないミスやエラーが出力されてしまう可能性があります。
質問3AI画像生成の注意点や気をつけたいポイントは?
上述の著作権や商標権、倫理的な問題に加えて、社会的・政治的な影響のある画像の拡散はしないことを意識してください。
日々クオリティが上昇しているAI画像生成では、ぱっと見に信じてしまうようなフェイクニュース画像も生成できてしまいます。
大衆の扇動や誤った情報の拡散は、逮捕のリスクまであります。
遊び半分でやって一生後悔する羽目になりかねませんので、必ず避けることを心がけましょう。
また、生成AIに対して個人情報や機密情報などの秘匿性が高い情報は入力し無いよう注意してください。
流出・漏洩した場合、サイバー犯罪などに悪用されるリスクがあります。
まとめ:AnimagineとFilmoraでクリエイティブの新たな扉を開こう!
本記事では、話題のオープンアニメ絵生成AIモデル「Animagine」について、即座に使い始められるサービスや、具体的な方法、イメージ通りのアニメを生成するための手段など、実践的な内容をわかりやすくまとめました。
ここまで読んでくださった方であれば、オリジナルのアニメ絵が既に手に入っているのではないでしょうか?
なお、今回はローカル構築ではなく、より手軽で誰でもすぐに実践でき、PCスペックも必要ない「Spaces」内の使用方法を解説しましたが、PCローカルにStableDiffusion WebUIを導入してモデルを使用する事も可能です。
また、記事後半で紹介したFilmoraはAI画像生成機能に加えて、動画生成や音楽生成など、様々なAI生成機能が搭載された最先端動画編集ソフトです。
こちらも画期的なツールで、誰でもプロ並みの動画が直感的な操作だけで制作可能となっています。本記事で紹介した「Animagine XL」と「Filmora」を活用して、ぜひ新たなクリエイティブの扉を開いてください!!



役に立ちましたか?コメントしましょう!