

OpenAIがChatGPT Images 2.0を公開しました。これまで、AI画像生成で思い通りの結果を出すために何度もプロンプトを書き直したり、設定を細かく調整したり、同じ画像を何度も再生成したりしていた人にとって、今回のアップデートはかなり大きな進化です。
そこで本記事では、Images 2.0を実際に検証し、旧世代のGPT ImageシリーズやNano Banana 2とも比較しながら、何が変わったのか、まだ弱い点はどこか、より良い結果を出すためのプロンプトのコツまでまとめて紹介します。

パート1. ChatGPT Image 2.0とは?
OpenAIは、ChatGPT内の画像生成システムを大幅に刷新し、新たにChatGPT Images 2.0として展開しました。中核となるのはgpt-image-2という新モデルで、開発者はAPI経由でも同じモデルを利用できます(詳細は後述します)。
Images 2.0は、Thinking機能を備えた初のOpenAI画像モデルであり、非常に高いテキスト描画精度と、再設計された生成アーキテクチャを特徴としています。実用面では、これまで発生しがちだった「何度もやり直して調整する手間」を減らし、少ない試行回数で使えるビジュアルを得やすくなったのが大きなポイントです。
GPT Image 2.0の主な進化ポイント
gpt-image-2のリリース日は2026年4月21日です。公開当日からChatGPTユーザーとCodexユーザー向けにグローバル展開され、主に次のようなアップデートが加わりました。
1. Thinking機能を備えた初の画像モデル
gpt-image-2は、生成時にWeb検索を行い、出力内容を自己検証できる初のOpenAI画像モデルです。さらに、1つのプロンプトから最大8枚まで画像を生成でき、複数枚のあいだでキャラクターやオブジェクトの一貫性も保ちやすくなっています。
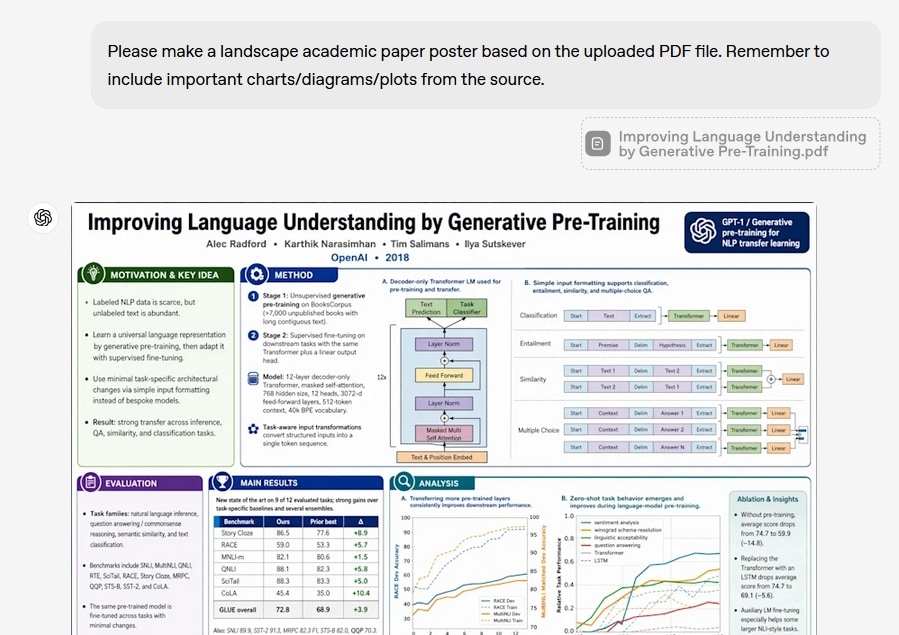
2. テキスト描画が大幅に改善
LM Arenaの初期テスターによると、文字レベル精度は99%に達すると報告されています。テキストが単に上に載るのではなく、シーンに自然になじみやすくなり、ラベル、メニュー、UI要素のような細かな文字も崩れにくくなりました。この改善は、日本語、中国語、韓国語、ヒンディー語、ベンガル語など、非ラテン文字にも及びます。

3. スタイル表現が洗練され、写実性も向上
Images 2.0は、より幅広いビジュアルスタイルに対応しつつ、一貫性も高まっています。特にリアル系の出力は実写に近づき、次のような改善が見られます。
- GPT Image 1.5で目立った暖色寄りの色かぶりが大きく軽減
- 物理挙動、ライティング、質感表現の精度が向上
- 手や指の形がより自然になり、比率や関節表現も改善

4. 処理速度の向上と柔軟なアスペクト比
新しいgpt-image-2は、従来モデルより高速に動作します。対応アスペクト比は3:1から1:3まで幅広く、横長バナー、プレゼン資料、ポスター、スマホ画面、SNS用グラフィックなども、トリミングや再調整を減らしながら作りやすくなりました。
5. 現実世界への理解力が向上
Images 2.0は、2025年12月時点までの知識をもとに、現実世界への理解をより反映できるようになりました。最近の出来事、製品、文化的背景なども把握しやすく、毎回細かく説明しなくても状況に合った生成結果を出しやすくなっています。
パート2. gpt-image-1 vs gpt-image-1.5 vs gpt-image-2.0
ChatGPT Images 2.0の進化を直感的に理解するには、3世代を並べて比較するのがわかりやすいです。ここでは、同じプロンプトを使って各モデルを比較し、どこに差が出るのかを確認します。

GPT Image 1.0 / 1.5 / 2.0 比較表
| GPT Image 1.0 | GPT Image 1.5 | GPT Image 2.0 | |
| リリース時期 | 2025年4月 | 2025年12月 | 2026年4月 |
| 文字描画 | 長文では崩れやすい | 改善されたが密度の高い構図では不安定 | 大幅改善。看板、ポスター、ラベル、UI風画像で特に強い |
| プロンプト再現性 | 複雑な指示を無視しやすい | 約70%程度追従 | かなり高精度に追従 |
| 写実性 | 十分だが人工的に見えることがある | より洗練され自然 | 高精細でシネマティック |
| 速度 | 基準 | 1.0比で約4倍高速 | 1.5比で約2倍高速 |
| 解像度 | 最大1536×1024 | 最大1536×1024 | 最大2560×1440(2K) |
APIコストの比較
| モデル | 品質 | 1024 × 1024 | 1024 x 1536 | 1536 × 1024 |
| GPT Image 2 | High | $0.211 | $0.165 | $0.165 |
| GPT Image 1.5 | High | $0.133 | $0.2 | $0.2 |
| GPT Image 1 | Moderate | $0.167 | $0.25 | $0.25 |
注: 実際のコストには、画像編集や参照画像利用時のテキスト入力トークン、画像入力トークンも含まれる場合があります。詳細はOpenAIのAPI画像生成ガイドをご確認ください。
パート3. ChatGPT Image 2.0の使い方
ChatGPTで画像を生成するときは、基本的に最新のChatGPT Images 2.0が自動適用されます。無料ユーザーを含む全プランで利用できますが、Thinkingを使った高度な出力はChatGPT Plus、Pro、Business向けです。
各プランの価格差は、以下の表を参考にしてください。
| Plus | Pro | Business | |
| 月額料金 | $20 | $100 | $25/ユーザー |
手順解説:ChatGPTでGPT Image 2を使う方法
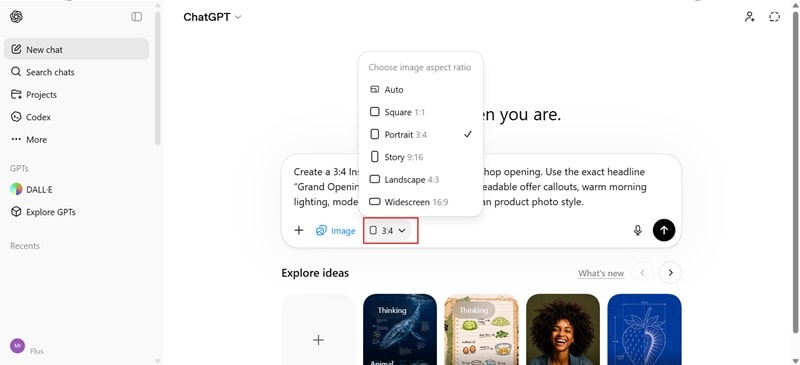
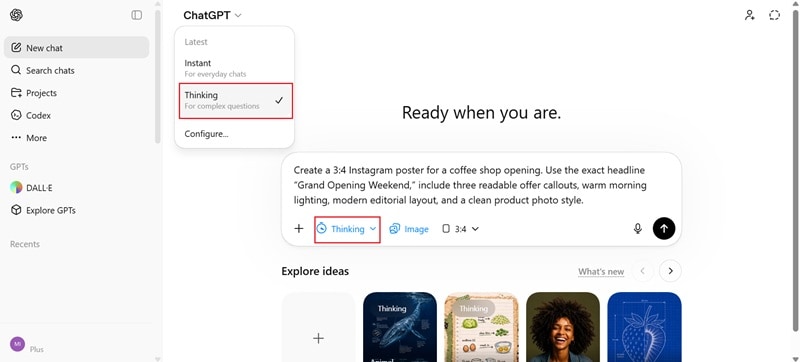
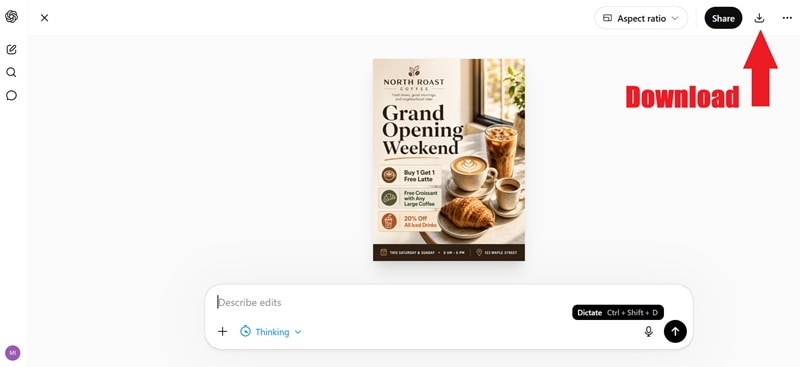
GPT Image 2が向いている活用シーン
ChatGPT Images 2.0が特に強いのは、創造性だけでなく構造性も求められる画像です。単に雰囲気の良い画像を作るだけでなく、情報を伝えるビジュアル制作にも向いています。

代表的な活用例は次のとおりです。
- UI/UXモックアップ: 読みやすいボタン付きのアプリ画面を丸ごと設計しやすい
- マーケティング素材: 広告、ポスター、バナーなど印刷向けビジュアルを作りやすい
- 図解・教育用途: 数学の証明やフローチャートのような構造的な図も作りやすい
- 商品ビジュアル: パッケージ案、販促モックアップ、ライフスタイル写真風の画像に向く
- イラスト制作: キャラクターの一貫性を保ちながらゲームや書籍向けのコンセプトアートを作りやすい
開発者・企業向け:APIでgpt-image-2を使う方法
開発者や企業は、APIドキュメント上の正式名称であるgpt-image-2を使って、同じ生成能力を自社プロダクトに組み込めます。API経由でも、高精度な文字再現や表現力の高いビジュアル生成を活かせるため、開発環境の自由度とあわせて実務利用しやすいのが魅力です。
gpt-image-2 API料金
gpt-image-2の料金は、単純な「画像1枚あたり」ではなく、品質、サイズ、トークン数など複数要素で決まります。大まかには次の傾向です。
- 低品質 + 小さめサイズ = 安くて高速
- 高品質 + 高解像度 = 高コストだがより精細
| 比率 | 品質 | トークン数 | 価格 |
| 正方形(1024×1024) | Low | 272 tokens | $0.006 |
| 正方形(1024×1024) | Medium | 1,056 tokens | $0.053 |
| 正方形(1024×1024) | High | 4,160 tokens | $0.211 |
| 縦長(1024×1536) | Low | 408 tokens | $0.005 |
| 縦長(1024×1536) | Medium | 1,584 tokens | $0.041 |
| 縦長(1024×1536) | High | 6,240 tokens | $0.165 |
| 横長(1536×1024) | Low | 400 tokens | $0.005 |
| 横長(1536×1024) | Medium | 1,568 tokens | $0.041 |
| 横長(1536×1024) | High | 6,208 tokens | $0.165 |
パート4. 画質比較テスト:gpt-image-2 vs Nano Banana 2
現時点でGPT Image 2の最も近い競合は、Google系の画像生成フラッグシップとされるNano Banana 2です。GPT Image 2は公開直後にLM Arenaのリーダーボードで1位に入り、Nano Banana 2に236ポイント差をつけました。
GPT-Image 2.0 vs Nano Banana 2
| GPT Image 2.0 | Nano Banana 2 | |
| LM Arenaスコア | 1,507(暫定) | 1,271 |
| 複数画像の一貫性 | 1プロンプトで最大8枚 | 最大5キャラクター、14オブジェクト |
| 無料利用枠 | 1日2〜3枚 | 1日最大20回 |
| API入力価格(100万トークンあたり) | $8 | $0.50 |
| API出力価格(100万トークンあたり) | $30 | $3(text / thinking) / $60(images) |
実際の差を確認するため、同じプロンプトで両モデルをテストしました。結果は以下のとおりです。
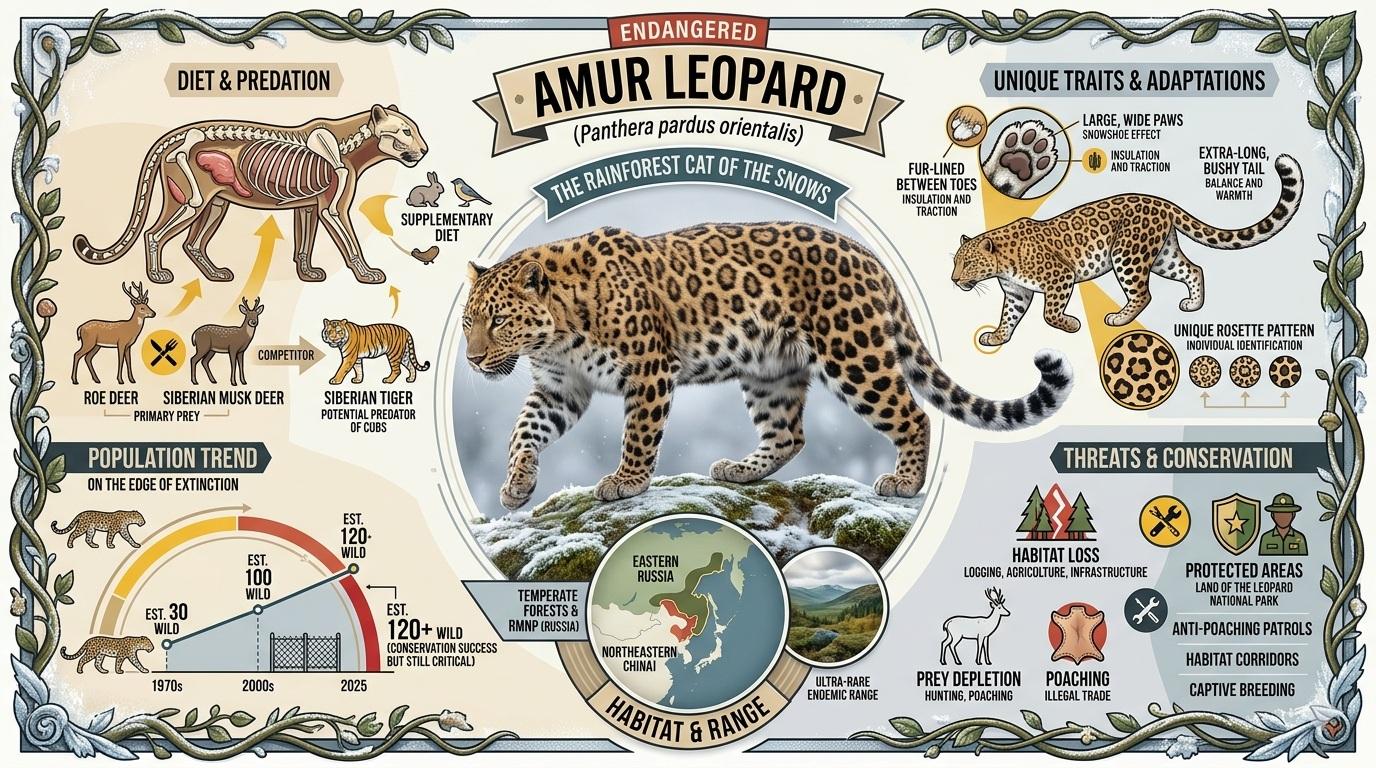
1. 絶滅危惧動物のインフォグラフィック
GPT Images 2.0:

Nano Banana 2:
2. 写実的な写真表現

3. アニメキャラクター

4. 多言語ポスター

結論:GPT-Image 2 vs Nano Banana 2
- ChatGPT Image 2.0は多言語テキスト表現で優位性があり、Nano Banana 2より安定して文字を描画しやすいです。
- 一方で、インフォグラフィックや技術図のようにラベルやデータ精度が重要な場面では、依然としてミスが起こることがあり、Nano Banana 2のほうが安定するケースもあります。
- GPT Image 2はデフォルトで彩度が高く華やかな傾向があり、Nano Banana 2はやや落ち着いた自然寄りのトーンになりやすいです。
- 人物やキャラクターの顔・体つきは、拡大して見るとまだAIらしさが残ることがあり、この点はどちらのモデルも完全には解決していません。
ワンポイント: 画像生成後のワークフローまで考えるなら、Filmoraを使ってそのままタイムライン上で加工し、動きを加えて動画化する方法も効率的です。

パート5. ChatGPT Images 2.0のメリット・デメリット
ここまで見てきた通り、GPT Image 2.0には多くの強みがありますが、まだ完璧ではありません。
- 複数条件を含む複雑なプロンプトでも、細部を落としにくい
- 画像内テキストがラテン文字・非ラテン文字を問わず読みやすい
- Thinkingモードでは1つのプロンプトから最大8枚生成でき、オブジェクトやキャラクターの一貫性を保ちやすい
- 折り紙の手順やパズルのように、完全な物理世界モデルが必要な課題はまだ苦手
- 技術図の矢印や部品ラベルは、人の目で精度確認したほうが安心
- Thinkingモードでは1回の生成に最大2分ほどかかる場合がある
- 細かな砂粒、布の織り、密集した質感のような反復ディテールはまだ不安定
- 情報の誤りが残る可能性はあるため、公開前に事実・数値・ラベル確認は必須
パート6. GPT-Image 2.0で結果を良くするプロンプトのコツ
gpt-image-2は高性能ですが、指示の出し方次第で結果の質は大きく変わります。大切なのは、思いつきをそのまま投げるのではなく、プロンプトを「制作ブリーフ」として設計することです。
1. テキスト指定は具体的に書く
画像内に入れたい文字は、引用符で囲むか大文字で示し、どこに入れるかまで指定すると安定しやすいです。
- ❌ タイトルを追加する。
- ✅ 見出しは「LAUNCH DAY」。太めのコンデンスドサンセリフ体で、左上配置、暗い背景に白文字。
珍しい単語やブランド名は、必要に応じて1文字ずつ綴ると崩れにくくなります。小さい文字や密度の高いレイアウトでは、medium以上の品質設定を使うと安定しやすいです。
2. 被写体だけでなく撮り方まで指示する
このモデルは写真表現の指示と相性が良く、ライティング(例: 北向き窓のやわらかい自然光)、素材感(例: マットなコンクリート)、カメラの雰囲気(例: 35mmフィルム粒子)、構図(例: 被写体は下1/3、上部に余白)まで指定すると精度が上がりやすいです。シーン設定を具体化するほど、モデル側の勝手な補完を抑えられます。
3. 不要要素を制約で明確に除外する
プロンプトの最後に、no watermark、no extra text、no background clutter、preserve layout、neutral color rendering のような制約条件を入れると、やり直し回数を減らしやすくなります。ネガティブ指示をうまく使うことも、完成度を上げるコツです。
パート7. GPT Image 2.0の画像を動画コンテンツに展開する方法
GPT Image 2.0で画像を作ったあと、静止画のままで終えるのは少しもったいない使い方です。Filmoraに取り込めば、短時間でショート動画や動きのあるコンテンツへ展開できます。
上のような動画に仕上げたい場合は、Filmoraの「画像から動画生成」機能を使うと便利です。モデル、アスペクト比、長さ、解像度を設定するだけで、画像をそのまま編集タイムライン上で動きのある映像に展開できます。
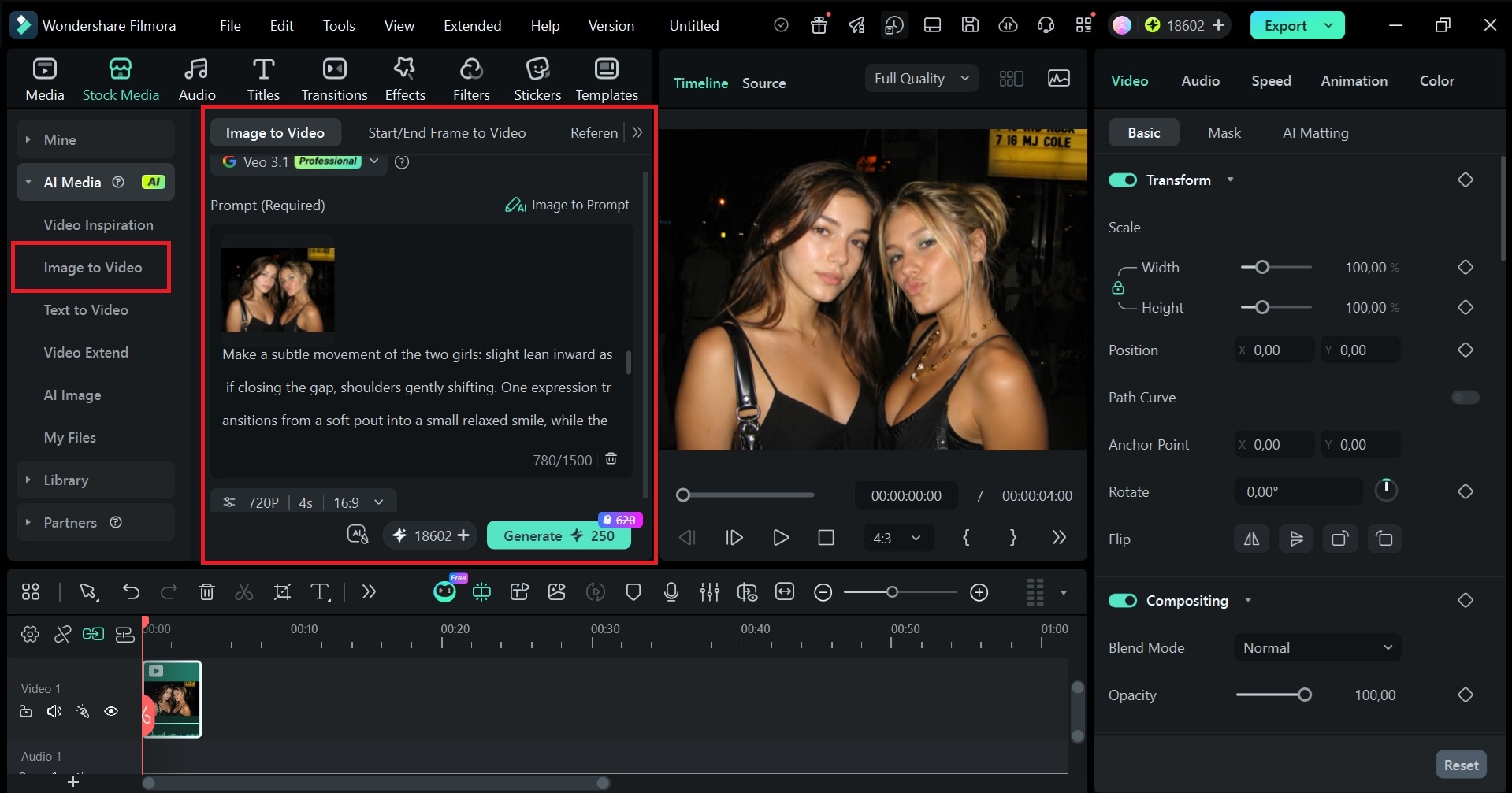
FilmoraのImage-to-Videoは、Veo 3.1、Seedance 2.0、ToMovieeなどの先進モデルを活用しており、追加の複雑な編集なしでも一定品質の出力を得やすいのが特長です。Filmoraでは、たとえば次のようなことができます。
- 静止画をトランジション、モーション、音楽付きの短尺動画へ変換
- アニメーション字幕やテキストオーバーレイを追加
- 複数のGPT Image 2.0出力をまとめて1本のストーリー動画に構成
- 縦型・正方形・横型など各プラットフォーム向けに書き出し
すでにマーケティング用ビジュアルや商品画像、イラスト素材をGPT Image 2.0で作っているなら、Filmoraを組み合わせることで、1枚の画像からよりリッチな動画コンテンツへ発展させやすくなります。
まとめ
ChatGPTが導入した新しいgpt-image-2は、まさに「視覚表現の思考パートナー」といえる進化を見せています。AI画像生成を何度もやり直す前提の作業から、より少ない試行で使える結果へ近づけやすくなったのが大きな変化です。
特に大きい進化は、多言語対応の文字描画精度、ThinkingモードによるWeb検索、複数画像の一貫性です。一方で、技術図やデータ重視のビジュアルでは依然として注意が必要です。さらに生成結果を活かしたいなら、Filmoraのような動画編集ツールに取り込んで、動きのあるコンテンツに展開するのもおすすめです。
FAQ
-
1. ChatGPT Images 2.0は商用利用できますか?
はい。ChatGPTで生成した画像は、マーケティング素材、商品ビジュアル、ブランド向けコンテンツなど商用目的でも利用できます。ただし、利用条件は変更される可能性があるため、公開前にOpenAIの最新ポリシーを必ず確認してください。 -
2. ChatGPT Images 2.0でキャラクターや画風の一貫性は出せますか?
Thinkingモードを有効にすると、gpt-image-2は1つのプロンプトから最大8枚の画像を生成しながら、キャラクターやオブジェクトの一貫性を保ちやすくなります。 -
3. ChatGPT Images 2.0で生成後に画像編集はできますか?
はい。画像の一部を修正したい場合は、説明欄に追加指示を入力して再生成できます。ただし、これはプロンプトベースの編集であり、ピクセル単位の手動編集とは異なります。API利用者向けには専用の画像編集エンドポイントも用意されています。 -
4. ChatGPT Images 2.0は無料で使えますか?
基本的な画像生成は無料ユーザーでも回数制限付きで利用できます。一方、Web検索や複数画像生成を含むThinkingモードは、月額20ドルからのPlus、Pro、Businessプラン向けです。 -
5. ChatGPTで旧Imagesモデルに戻して使うことはできますか?
メイン画面からは難しい可能性が高いです。ChatGPTで画像を生成すると通常は最新のGPT Imageモデルが自動適用され、旧モデルはUI上から順次利用できなくなることが一般的です。開発者であれば、API経由で旧モデルにアクセスできる場合があります。
