
SNSで話題のAIおばあちゃんを、だれでも手軽に制作できる時代です。本記事は Filmora の画像生成(Text-to-Image)と画像から動画生成-VEO3モード(Image-to-Video)を軸に、 ショートで映えるAI動画を量産する実践ノウハウを解説。本文の指令(プロンプト)は、Youtuber/配信者としての世界観を伝えるために、すべて英日対照の詳細シーン記述+キャラクター台詞で統一しました。


目次
Part1:AIおばあちゃんとは?魅力と拡散ポイント
AIおばあちゃんは、日本人の優しい祖母の顔立ちに、シュールな非日常シチュエーションを掛け合わせた“バズ”特化型キャラクター。 ブロガー/配信者として一人称で語ることで、視聴完走・コメント率・保存率が伸びやすく、ショート動画の スクロールストッパーとして機能します。
- 親しみ×非日常のコントラストでクリック&視聴維持
- 3〜6秒のワンアイデア完結でSNS最適化
- コメントで「次のAIおばあちゃん」を視聴者と共創しやすい
@filmora_japan_official フィモーラの『Veo3』で遊んでみたら本気で編集時短になった! 「企画 → 動画完成」までをAIが自動でやってくれる時代に突入! #Filmora #veo3 #aiおばあちゃん #動画編集 #AI動画 ♬ オリジナル楽曲 - 公式フィモーラ
Part2:AIおばあちゃん動画生成にFilmoraの活用術:画像生成+画像から動画生成-VEO3モードで配信者視点コンテンツ制作
Filmoraは、画像生成(Text-to-Image)と画像から動画生成(Image-to-Video)を組み合わせ、短時間で高完成度の動画を作れるのが最大の強みです。
特にAIおばあちゃんを主人公にしたYouTuber・配信者視点コンテンツでは、外見・衣装・舞台・光・レンズを一括設計し、セルフィー構図や手持ちマイクなどを共通指定にすることで、ブランド感を統一できます。
画像から動画生成-VEO3モードでは、生成した静止画に動きを加え、日本語の一言セリフを重ねることでライブ感を強化。字幕と口パクを意識することで、視聴者の滞在時間を自然に延ばすことができます。
AIおばあちゃん式Filmora 最短制作ワークフロー(3ステップ)
- 画像生成(T2I)で世界観設計:テキストから静止画を生成し、登場人物の外見・表情・舞台背景・光源を細かく指定。特に博主視点では
selfie POV、right-hand micを固定要素にすることで一貫性を確保。
指令例文:中近景、夕焼けの瓦礫地帯:漂う粉塵を縁取る温かなリムライト。サバイバル装備の日本人おばあちゃんがカメラに少し寄り、顔が画面の大部分を占め、細やかな表情皺と温かな笑顔がはっきり見える。左手で簡易防弾ベストを指差し、右手に小型マイク。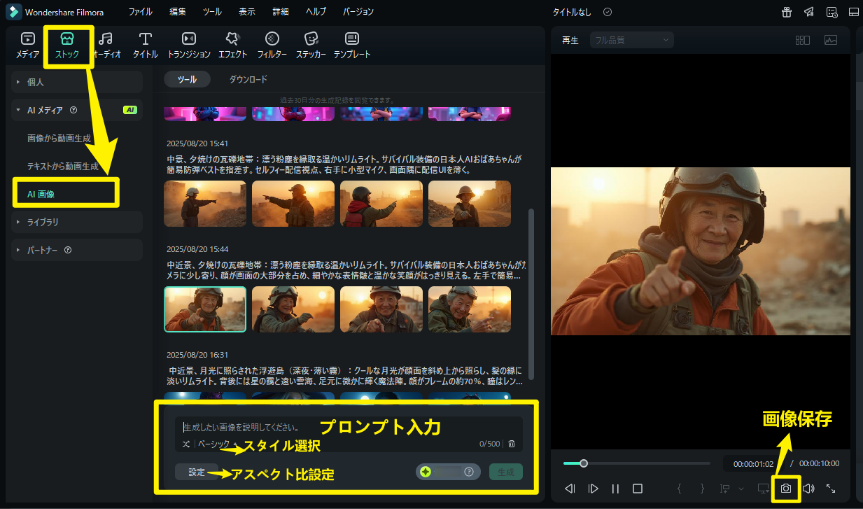
Filmora|画像生成(T2I)で世界観設計(スタイル:ベーシック、アスペクト比:16:9) - 画像から動画生成-VEO3モードで動きと音声を追加:生成した静止画に動きを加え、シーンの開始→中盤→終盤を3〜6秒で構成。8〜14音節の日本語台詞を設定し、口パクと同期させる。環境音やカメラ揺れを入れると臨場感が増す。
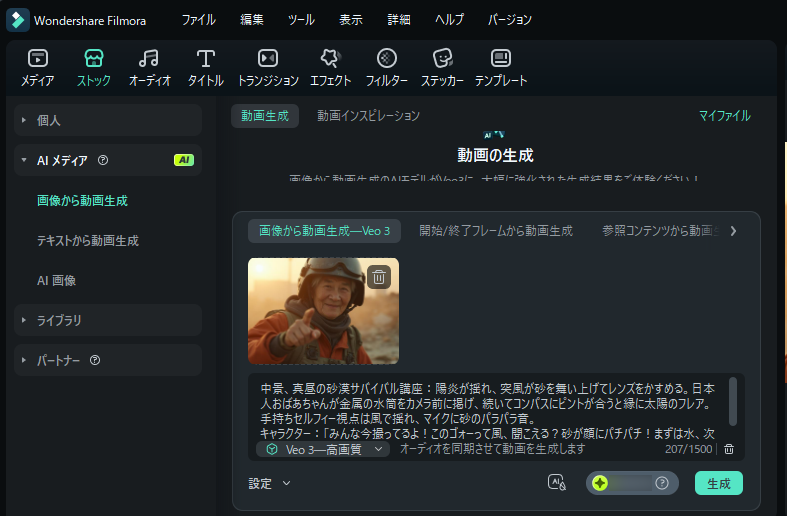
Filmora|画像から動画生成-VEO3モードで動きと音声を追加 指令例文:中景、真昼の砂漠サバイバル講座:陽炎が揺れ、突風が砂を舞い上げてレンズをかすめる。日本人おばあちゃんが金属の水筒をカメラ前に掲げ、続いてコンパスにピントが合うと縁に太陽のフレア。手持ちセルフィー視点は風で揺れ、マイクに砂のパラパラ音。キャラクター:「みんな今撮ってるよ!このゴォーって風、聞こえる?砂が顔にパチパチ!まずは水、次に方向。太陽に合わせてコンパス読む!“水とコンパス”ってコメントして忘れないでね!」Filmoraで生成したAIおばあちゃん動画例 - 動画編集:生成した動画をタイムラインにおいて、不要部分をカットし、効果音・字幕・エフェクトを追加して完成度を高める。BGMや効果音はシーンに合わせて選び、視聴者の没入感を強化。
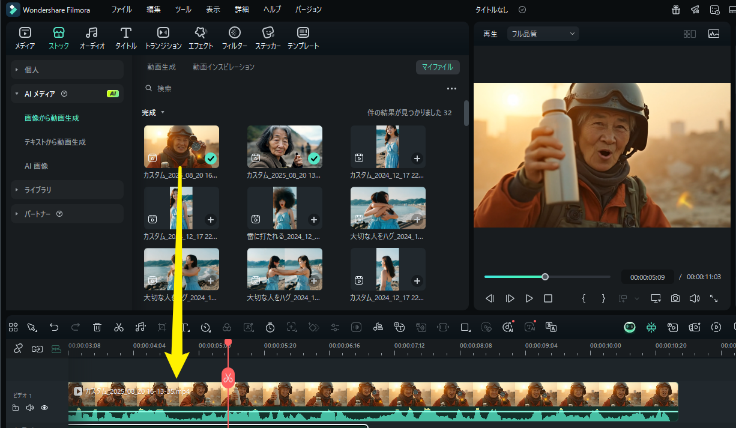
Filmora|効果音・字幕・エフェクトを追加
Part3:完成度を高めるためによく使う動画編集コツ(AIおばあちゃん×Filmora)
ここでは、FilmoraでAIおばあちゃんを主役にした動画を仕上げる際に役立つ編集テクニックをまとめました。
画像生成(T2I)や画像から動画生成(Veo3モード)で作った素材に、このステップを加えることで完成度と視聴者の没入感が大幅にアップします。
- アスペクト比を変更: 「ファイル」➤「プロジェクト設定」から動画のアスペクト比(16:9、9:16、1:1など)を変更可能。
SNS投稿やYouTube Shorts用に最適化しましょう。
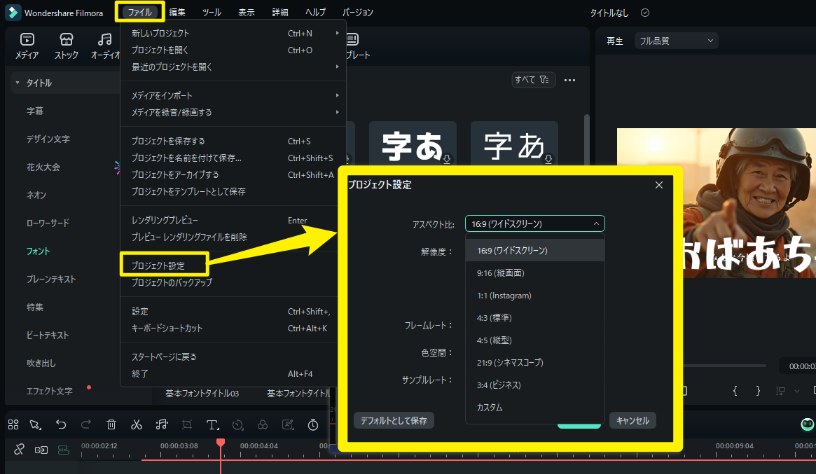
Filmora|アスペクト比を変更 - 不要な部分をカット: タイムライン上で不要なシーンやミスカットをトリミング。短尺動画はテンポが命なので、余計な間は思い切って削除します。
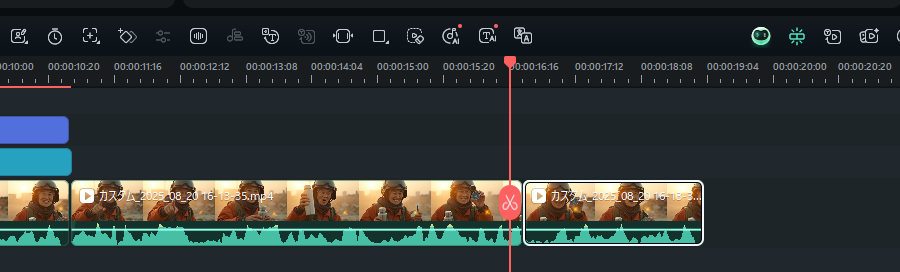
Filmora|不要な部分をカット - 効果音を追加: オーディオ効果音の検索欄に「風」「砂」「クリック」などのキーワードを入れて追加。
また、Filmora内のAI効果音生成機能を使えば、シーンにぴったりなオリジナル音を自動作成できます。
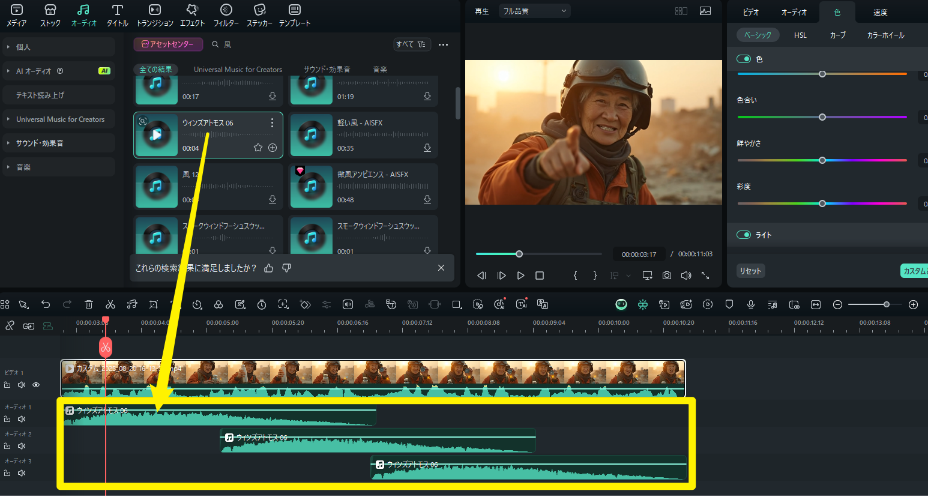
Filmora|効果音を追加 - 字幕起こし・字幕を追加: AI字幕起こし機能を使って、自動的に正確な字幕を生成。 さらに「タイトル」メニューから好みの字幕スタイルを選んで視認性を高めましょう。 配信者視点ならセリフの重要ワードを強調表示すると効果的です。
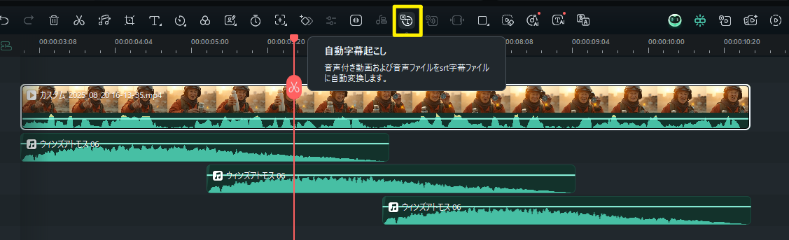
Filmora|字幕起こし・字幕を追加 - エクスポート: 左上で動画サムネイルを編集し、視聴者のクリック率を高めます。 エクスポート設定では画質を高に設定し、4Kや高ビットレートで保存するのがおすすめです。
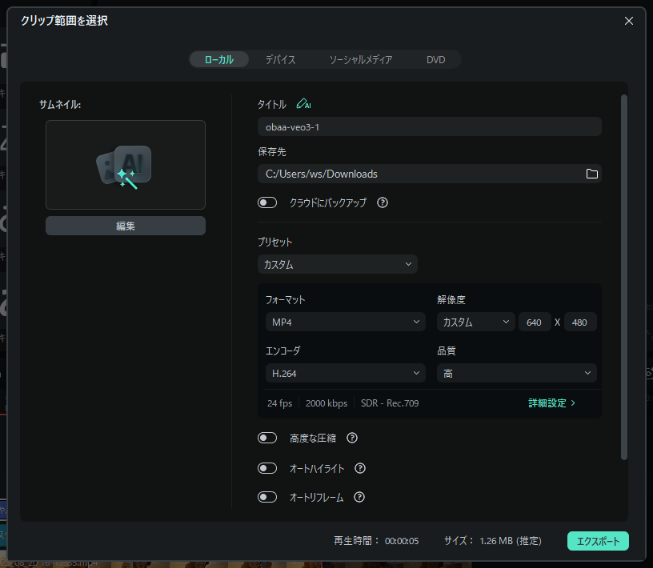
Filmora|エクスポート
Part4:AIおばあちゃん式 Filmora プロンプト構文テンプレ&作例(JA/EN対応)
このセクションでは、Filmoraの「画像生成(T2I)」と「画像から動画生成(I2V)」の両方に使えるプロンプト構文テンプレと作例を、英日対照の表でまとめています。
以下の構成に沿って入力することで、AIおばあちゃんを主人公にしたライブ感のあるコンテンツを安定して生成できます。
画像生成(静止画)テンプレ
| 英語(Text-to-Image) | 日本語(画像生成) |
|---|---|
| A <shot size>, <genre/setting>: <lighting, environment, props, action, composition, fine details>. Character: "<short Japanese line>" | <ショットサイズ>、<舞台/ジャンル>:<照明・環境・小道具・動作・構図の詳細>。キャラクター:「<短い日本語台詞>」 |
画像から動画生成-VEO3モード(動き+セリフ)テンプレ
| 英語(Image-to-Video) | 日本語(画像から動画生成) |
|---|---|
| A <shot size>, <setting>, first-person streamer POV: <starting action> → <middle motion> → <ending beat>. Character: "<short Japanese line>" (duration 3–6s) | <ショットサイズ>、<舞台>、一人称配信者視点:<開始の動き> → <中盤の動き> → <締めの見せ場>。キャラクター:「<短い日本語台詞>」(尺3〜6秒) |
上記のプロンプト構文テンプレを使えば、AIおばあちゃんを主人公にした高精細な静止画(画像生成)や、ライブ感あふれる短尺映像(画像から動画生成-Veo3モード)を安定して制作できます。
次に紹介する大量プロンプト集(日本語/英語・コピペ可)では、ジャンル別にそのまま使える実践例を収録しました。
シーン構築の参考にして、Filmora Veo3であなた独自の配信者視点コンテンツを作ってみましょう。
大量プロンプト集(AIおばあちゃん×Filmora対応/日本語・英語コピペ可)
① サバイバル&アクション(画像生成/画像から動画生成-VEO3モード)
|
サバイバル:夕焼け瓦礫地帯 / Survival: Sunset Rubble (T2I → I2V 継続) |
|
|---|---|
| 画像生成-JP | 中近景、夕焼けの瓦礫地帯(ゴールデンアワー):左からの柔らかな暖色キーライト、髪の縁にさりげないリムライト。背景の瓦礫は柔らかくボケる。顔がフレームの約70%を占め、瞳はレンズをまっすぐ見つめ、細かな皺と肌理がはっきり分かる。表情は「やさしく自信があり、少しお茶目」。サバイバル装備の日本人おばあちゃんが左手で簡易防弾ベストのタグを指差し、右手に小型マイク。セルフィー配信の一人称視点、手持ち微ブレ。焦点距離45–50mm相当、高精細、シネマティック |
| 画像生成-EN | Medium close-up, sunset rubble zone (golden hour): soft warm key light from the left; subtle rim light on hair edges; background rubble softly blurred. Face fills ~70% of frame; eyes look directly into the lens; fine wrinkles and skin texture clearly visible; expression: “gentle, confident, slightly playful.” A Japanese grandma in rugged survival gear points to the flak-vest tag (left hand) while holding a small mic (right). Selfie streamer POV with slight handheld wobble; 45–50mm natural perspective; high detail, cinematic. |
| 動画生成-JP | 夕焼けの瓦礫地帯。環境音:遠くでカラス、風が砂を巻き上げレンズにパチパチ当たる微音、時々金属がコトンと鳴る。カメラ動き:0.5秒ゆっくりプッシュイン → ベストのタグへラックフォーカス → 彼女の顔へフォーカス戻し、レンズフレアが一瞬走る。動作:ベストの衝撃パッドを指でトントン → マイクを口元へ。 キャラクター:「やっほー!ゴールデンアワー最高、光の当たり方わかる?(砂で)いってぇ!でもね、このベストは“ここ”が肝。タグの位置と厚み、覚えて!さぁ“最強ベスト”ってコメントして、続きは実射で確かめよう!」 |
| 動画生成-EN | Same sunset rubble scene. Ambience: distant crow calls; wind lifts dust that tick-taps the lens; occasional metallic clink. Camera: gentle 0.5s push-in → rack focus to the vest tag → rack back to her face as a brief lens flare skims the frame. Action: she taps the impact pad with two fingers → brings the mic to her mouth. Character: “Hey! Golden hour perfection—see how the light wraps? Ow—sand got me! Anyway, this vest works because of this spot. Remember the tag placement and thickness. Type ‘STRONGEST VEST’ and we’ll prove it with a live test!” |
|
サバイバル:雪稜 / Survival: Snowy Ridge (T2I → I2V 継続) |
|
| 画像生成-JP | 中近景、正午の雪稜:高空からの冷たい拡散光、左頬に淡い反射光、背景の雪面はやわらかくボケる。顔がフレームの約70%、瞳はレンズに直線、微細な皺・肌理・頬の赤みまで明瞭。表情は「笑顔に少し真剣味」。70代の日本人おばあちゃんが三層の防寒ジャケットを示し、指で軽くトントン。セルフィー配信視点、手持ち微ブレ、吐く息が白く広がる。焦点距離50mm相当、高精細。 |
| 画像生成-EN | Medium close-up, snowy ridge at noon: crisp overhead daylight; soft bounce on left cheek; background snow gently blurred. Face fills ~70% of frame; eyes locked to the lens; fine wrinkles, skin texture, and natural cheek flush clearly visible; expression “smiling with a hint of seriousness.” The Japanese grandma demonstrates triple-layer jackets, tapping each layer. Selfie POV with slight handheld wobble; breath spreads white. 50mm look; high detail. |
| 動画生成-JP | 正午の雪稜。環境音:風のゴォーという帯音、足元の雪がギュッと鳴る、遠くでカササギの声。カメラ動き:ゆっくりプッシュイン → 胸元の第一層にラックフォーカス → 第二・第三層へリズミカルにフォーカス移動 → 顔へ戻す。動作:彼女は各層を指でトントン、最後に足踏みして雪の音を聞かせる。 キャラクター:「ひゃ〜刺さる寒さ!でも“三段”なら余裕。まず汗冷え止め、次に空気の層、最後に防風。今のギュッて音、聞こえた?納得した人は“ぬくぬく安全”ってコメント!歩き方のコツはこのあと実演いくよ!」 |
| 動画生成-EN | Same noon ridge. Ambience: a band of wind noise; crisp crunch of snow underfoot; distant magpie call. Camera: gentle push-in → rack focus to the first layer at the chest → hop focus to second and third layers in rhythm → back to her face. Action: she taps each layer with a fingertip, then stomps once to highlight the snow squeak. Character: “Whew—needle-cold! But ‘three layers’ stays cozy: anti-sweat base, air trap mid, wind-block shell. Hear that crunch? If it clicked, comment ‘WARM & SAFE!’ Walking-tech tips coming up next—don’t miss it!” |
② コメディ&ドタバタ(画像生成/画像から動画生成-VEO3モード)
|
コメディ:夜のジェットコースター乗り場 / Comedy: Roller Coaster Night (T2I → I2V 継続) |
|
|---|---|
| 画像生成-JP | 中近景、夜のジェットコースター乗り場(ネオン点灯):右上からのネオンの反射光が頬に柔らかく乗り、髪の縁に控えめなリムライト。背後の看板と人混みは柔らかくボケる。顔がフレームの約70%、瞳はレンズをまっすぐ見つめ、歯を見せた愉快な笑顔。日本人おばあちゃんが急降下の方向を指差し、左手で手すりを軽く握る。セルフィー配信一人称、手持ち微ブレ、。焦点距離45–50mm、高精細、シネマティック。 |
| 画像生成-EN | Medium close-up, roller coaster platform at night (neon lit): soft neon bounce lights her cheeks; subtle rim on hair edges; background signage and crowd softly blurred. Face fills ~70% of frame; eyes lock to lens; wide, playful smile. The Japanese grandma points toward the steep drop, lightly gripping the rail with her other hand. Selfie streamer POV with slight handheld wobble; faint stream UI at edges. 45–50mm perspective; high detail, cinematic. |
| 動画生成-JP | 夜の乗り場。環境音:安全バーのカチッ、チェーンリフトのガラガラ、遠くの歓声。カメラ動き:彼女が座席へ腰掛けると軽く沈み込み、プッシュインで顔へ寄る → そのままドロップ方向へチルト。背後のネオン反射が彼女の頬でチラッと瞬く。動作:指で「3・2・1」をカウント、腹式呼吸を示すように手を腹に当てる。 キャラクター:「やっほー!聞こえる、このガラガラ!腰落として〜、お腹から吸って…吐いて…いくよ、3、2、1、フォーーーーッ!今ので笑った人、高評価&『フォーー!』コメントお願い!」 |
| 動画生成-EN | Same neon platform. Ambience: safety bar click, chain-lift rattle, distant screams. Camera: seats compress as she sits; a gentle push-in to her face → tilt toward the glowing drop; neon reflections flicker across her cheeks. Action: finger counts “3-2-1,” hand on belly to cue diaphragmatic breath. Character: “Hey hey! Hear that rattle? Sink your hips—inhale… exhale… ready? Three, two, FOOOOOOUR! If you laughed already, smash like and type ‘FOOOO!’ in chat!” |
|
コメディ:提灯たい焼き屋台 / Comedy: Lantern Taiyaki Stall (T2I → I2V 継続) |
|
| 画像生成-JP | 中近景、提灯に照らされた屋台:暖色の提灯光が顔面に柔らかく回り込み、鼻筋と頬にやさしいハイライト。背後ののれんと鉄板は浅い被写界深度でボケる。顔がフレームの約70%、瞳はレンズ直視、口角の上がったワクワク笑顔。日本人おばあちゃんが割ったばかりのたい焼きをレンズ際へ掲げ、湯気がふわっと上がる。セルフィー配信一人称、手持ち微ブレ。焦点距離45–50mm、高精細。 |
| 画像生成-EN | Medium close-up, lantern-lit stall: warm lantern light wraps her face with gentle highlights on nose and cheeks; noren curtain and griddle softly blurred. Face fills ~70% of frame; eyes directly to lens; excited smile. The Japanese grandma lifts a freshly cracked taiyaki near the lens as steam billows. Selfie streamer POV with slight handheld wobble; 45–50mm; high detail. |
| 動画生成-JP | 提灯屋台。環境音:鉄板のパチパチ音、屋台の呼び込み、遠くでセミの声。カメラ動き:たい焼きを割ると湯気がレンズへふわっと寄り、カメラがスワイプで湯気の渦を追い、中央に戻って彼女の顔にプッシュイン。動作:彼女は熱さに肩をすくめ、頬をふぅふぅ冷ましてから一口かじる。 キャラクター:「あ、レンズごめん!湯気ドーン!アツッ…でも香ばしい〜!さぁ決めよう、“あんこ派?クリーム派?”今すぐコメントで参戦!多数派のレシピ、次の動画で作っちゃうよ!」 |
| 動画生成-EN | Same lantern stall. Ambience: griddle crackle, vendor calls, faint cicadas. Camera: when she snaps the taiyaki, steam rolls toward the lens; the camera swipes to follow the swirl, then centers and pushes in to her face. Action: she shrugs at the heat, blows gently, then takes a playful bite. Character: “Oops—sorry lens! Steam blast! Hot… but toasty good! Time to decide—Team Red Bean or Team Custard? Drop your vote now! I’ll cook the winning recipe in the next video!” |
③ ファンタジー&神話(画像生成/画像から動画生成-VEO3モード)
|
ファンタジー:月光の浮遊島 / Fantasy: Moonlit Floating Island (T2I → I2V 継続) |
|
|---|---|
| 画像生成-JP | 中近景、月光に照らされた浮遊島(深夜・薄い霧):クールな月光が顔面を斜め上から照らし、髪の縁に淡いリムライト。背後には星の靄と遠い雲海、足元に微かに輝く魔法陣。顔がフレームの約70%、瞳はレンズをまっすぐ見つめ、細かな皺・肌理まで明瞭。表情は「落ち着きといたずらっぽさが共存」。70代の日本人おばあちゃん(魔法使い風コスチューム)が右手に杖、左手で円形の光を示す。セルフィー配信一人称、手持ち微ブレ、画面端に薄い配信UI。焦点距離45–50mm、高精細、シネマティック。 |
| 画像生成-EN | Medium close-up, moonlit floating island (midnight, light mist): cool moonlight from above-left wraps her face; subtle rim along hair edges; star-mist and distant cloud sea behind; a faint glowing magic circle at her feet. Face fills ~70% of frame; eyes lock to lens; fine wrinkles and skin texture clearly visible; expression “calm with a playful hint.” A Japanese grandma in sorceress attire holds a wand in her right hand and gestures to a circular glow with her left. Selfie streamer POV with slight handheld wobble; faint stream UI at edges; 45–50mm; high detail, cinematic. |
| 動画生成-JP | 月光の浮遊島。環境音:高所の風がサァーと通り、魔法陣が低くハミング、遠くで鐘のようなきらめき音。カメラ動き:0.6秒ゆっくりプッシュインで顔へ → 杖先の光へラックフォーカス → 再び顔へ戻し、月光が頬に滑る。動作:彼女は杖を掲げ、掌を胸に当てて深呼吸をデモ。円環の光が呼吸に合わせて脈打つ。 キャラクター:「みんな、吸って…吐いて…今の鼓動、光とリンクしてるの見える?コツは肩じゃなくて“下腹”。ほら、ふわっと浮く感覚!感じた人は『✨』で空に合図して!次は小さな光球を一緒に飛ばすよ〜。」 |
| 動画生成-EN | Same moonlit isle. Ambience: high-altitude wind hush; low hum from the magic circle; faint bell-like twinkles afar. Camera: gentle 0.6s push-in to her face → rack focus to wand-tip glow → rack back to her face as moonlight glides across her cheek. Action: she raises the wand and places a palm on her chest to demo deep breathing; the ring of light pulses with her breath. Character: “Breathe in… and out… see the glow syncing with the heartbeat? Keep your shoulders soft—use the lower belly. Feel that lift? If you felt it, send ‘✨’ to the sky! Next we’ll launch a tiny light orb together.” |
| ファンタジー:竜の背で城上空を旋回 / Fantasy: Dragon Over Castle (T2I → I2V 継続) | |
| 画像生成-JP | 中近景、たいまつに照らされた古城の上空(青い夜明け前):雲間からの冷たい環境光、頬にかすかなリムライト。下方に城の塔とたいまつの光帯。顔がフレームの約70%、瞳はレンズ直視、肌理・皺まで高精細。表情は「ワクワクと勇ましさ」。日本人おばあちゃんが竜の鱗に片手を添え、もう片方で下の塔を指差す。セルフィー配信一人称、手持ち微ブレ。焦点距離45–50mm、シネマティック。 |
| 画像生成-EN | Medium close-up, above a torch-lit castle (pre-dawn blue hour): cool ambient glow from broken clouds; faint rim on her cheek; below, towers and torchlines. Face fills ~70% of frame; eyes to lens; skin texture and fine lines crisp; expression “excited and brave.” The Japanese grandma braces a hand on dragon scales and points toward a tower. Selfie streamer POV with slight handheld wobble; 45–50mm; cinematic. |
| 動画生成-JP | 同じ城上空。環境音:竜の翼がドン…ドン…と鼓動のように鳴り、風切り音がマイクを撫でる。遠くで城門のたいまつがパチパチ。カメラ動き:旋回に合わせてバンクしながら、下方のたいまつの列をなめるチルト → 顔へゆっくり戻す。動作:彼女は片手で鱗をグリップ、体幹を示すようにお腹に手を当て、呼吸で重心を安定。 キャラクター:「見て見て、たいまつが帯みたい!風つよ〜〜!でも大丈夫、“肘・膝・お腹”の三点でロック。吸って…吐いて…今のバンクも耐えた!一緒に飛びたい人は『DRAGON』って全大文字で叫んで!次は塔の上にスムーズ着地、やってみるよ!」 |
| 動画生成-EN | Same castle airspace. Ambience: dragon wingbeats thump like a heart; wind brushes the mic; torchlines crackle below. Camera: bank with the turn, tilt to skim the torchlit ramparts → drift back to her face. Action: she grips a scale with one hand, places the other on her core to show bracing; breath steadies her center of mass. Character: “Look—torchlight like a glowing ribbon! The wind is wild—but lock elbows, knees, and core. Breathe in… out… we held that bank! If you’d ride along, type ‘DRAGON’ in ALL CAPS! Next, a smooth landing on the tower—watch this!” |
画像から動画生成-VEO3モード:動き+セリフレシピ(AIおばあちゃん/博主視点・万能)
| 言語 / Language | Home Studio / Intro Wink | Quick Tutorial / Punchline Close |
|---|---|---|
| EN(Image-to-Video) | A medium close-up, home studio desk, first-person streamer POV: Gentle handheld wobble → prop (mic) rises into frame as she nods → wink and thumb-up toward lens. Character: "Yahho〜、kyō wa ‘<topic>’ o sakutto shōkai suru ne!" (3–4s) | A medium shot, quick tutorial layout: She points at on-screen captions → performs the action once → leans closer for the punchline. Character: "Channel tōroku, yoroshiku ne!" (3–5s) |
| JA(画像から動画生成) | 中近景、自宅スタジオ机前、一人称配信者視点:手持ちの微ブレ → 小型マイクをフレームインさせ頷く → ウィンクと親指グッ。キャラクター:「やっほ〜、今日は『<テーマ>』をサクッと紹介するね!」(3〜4秒) | 中景、クイック解説レイアウト:画面の字幕を指差す → 動作を一回だけ実演 → 近寄ってオチ。キャラクター:「チャンネル登録、よろしくね!」(3〜5秒) |
Part5:品質アップのコツ/NG例・注意事項
安全・権利に関する注意事項
- 著作権・商標:固有デザインは避け、オリジナル設計に。
- プライバシー:実在個人の容貌の無断使用は不可。
- プラットフォーム:各SNSのコミュニティガイドライン遵守。
Part6:よくある質問(FAQ)
Q1. 英語記述で本当に精度が上がる?
はい。環境光・構図・小道具まで英語で詳細化すると安定します。日本語の台詞は字幕・口パク用として明示してください。
Q2. 最適な尺は?
3〜6秒が基本。0.5秒で状況提示、2〜4秒で見せ場、最後に1秒弱でウィンクや決め台詞。
Q3. 商用利用やライセンスは?
Filmoraのライセンス・各プラットフォーム規約に従ってください。第三者の権利侵害に注意。
Q4. 生成がブレる時の処方箋?
固定語(Japanese AI grandma/selfie POV/right-hand mic/subtle stream UI/natural skin/no caricature)を毎回追加し、否定語で不要要素を排除。
まとめ
YouTuberやvloggerとしての一人称ライブ配信視点で描くAIおばあちゃんは、Filmora の 画像生成と画像から動画生成-VEO3モードを組み合わせることで、誰でも短時間にAI動画を量産できます。 本記事の英日対照の詳細シーン+台詞をそのままコピペして、まず1本公開してみましょう。



役に立ちましたか?コメントしましょう!